本記事では、Snowflake の使い方を解説していきます。
Snowflake は幅広い機能をもっているため、データ基盤の構築をどこから着手するか悩むこともあります。本記事では、想定するケースを例にして、BIツールからSnowflakeにアクセスできることをゴールにします。
具体的な流れとしては、データソースに配置したサンプルデータをSnowflake(初期設定済)にコピーし、BIツールからの Snowflake への接続です。
それでは想定ケースを見ていきましょう。
Snowflake を使う想定ユースケース
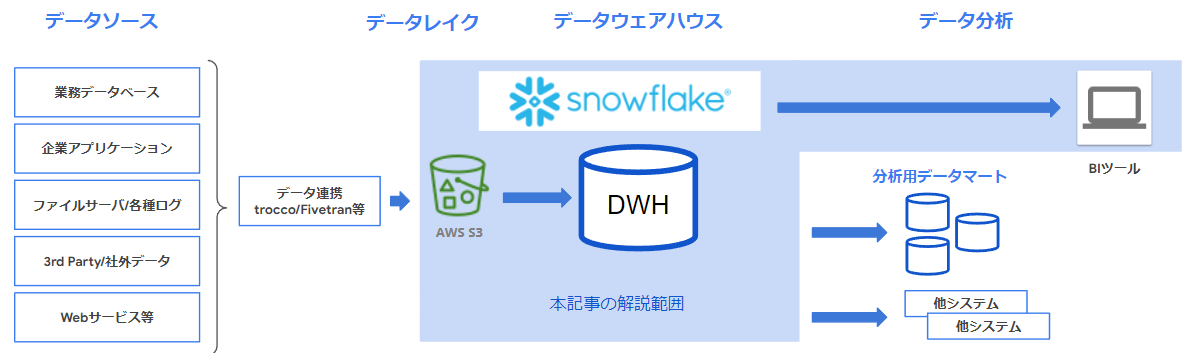
早速、図の構成要素について、左から簡単に紹介します。
a.データソース
データソースは、Snowfalke で分析したいデータ候補です。
自社内で利用しているデータベースやアプリケーションデータ、各種ログ、外部のデータやWeb サービス等、様々なデータが候補となります。
これらの生のデータをどのように Snowflake に渡していくかについて、次項以降のデータ連携、データレイク保管にて、事例を紹介します。
なお、本記事の検証で利用するデータは、BI ツールにTableau を選定するため、Tableau サイトの公開サンプルデータ(米国でトップの赤ちゃんの名前csv ファイル)とし、すでにデータレイクに保管されているものとします。
参考:Free Data Visualization Software | Tableau Public
b.データ連携方法
次にデータレイクの前段の「データ連携」についてです。
これはデータソース群をデータレイクに様々な手段で転送する手段をさします。
なお、データレイクを経由せず、直接 Snowflake データウェアハウスにデータを投入するケースもありますが、本記事では事例の多い データレイク経由を想定ケースとします。(データレイク設置メリットは次項参照)
従来の企業利用の例だと、ファイルを直接送るファイル伝送(HULFT等)や、ETLツール(ASTERIA Warp 等)によるデータ変換を伴うデータ連携があげられます。
ただ、こうしたデータの取り込みには多くのエンジニア工数がかかるため、最近の事例ですと、Fivetran や、国産SaaSのtrocco(トロッコ) 等、データソースの自動収集を得意とするツールの採用が進んでいます。
これらのツールは、SaaS で管理が省力化できる上、データ管理や変換、ジョブによるワークフロー化等、非常に多機能なデータパイプライン(分析データを整備する
一連の処理手順)を構成できることも特徴です。
データソース収集の省力化だけでなく、データ分析を行う前段のデータ加工の手間暇を削減できるため、ツールとエンジニア工数のコスト分析をして採用検討することも一般的な流れとなっています。
c.データレイク
本記事の想定ケースのデータレイクは、クラウドストレージのAWS S3 を想定しています。
データレイク設置のメリットには下記のようなものがあります。
- データソースの保管場所一元管理、分析対象データの長期保管が可能
- 生データを保管しておくことで、後日別角度で分析したいという要望に対しても生データを容易に提供可能
- 既存のバックアップシステムのデータ保管先に採用されるケースも多く、すでに分析候補のデータが保管されている可能性がある
- データウェアハウスの前段におけば、基盤構成がシンプル(データ取り込み対象はすべてデータレイクにある状況)になり、データフロー、データ保管に関するセキュリティの管理も比較的容易
- Snowflake は、AWS 、Azure 、Google Cloud を稼働基盤に選定できるため、これらのクラウドのストレージを利用していれば、同一リージョンでデータウェアハウスとのデータ連携を構成できる
ただ、データレイクは大量のデータを容易に保管できるが故に、ガバナンスのないまま保管していくと、コストが増加するリスクもあるので、Snowflake への投入前のデータクレンジングにtrocco を活用するケースもありえます。
本記事の想定ケースでは、データソース項で前述した通り、サンプルデータを S3 に配置しているところから解説します。
データウェアハウス
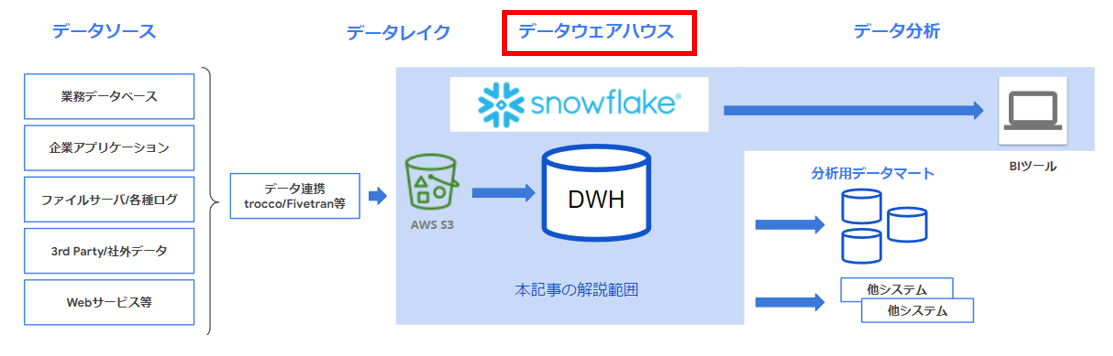
図のデータウェアハウス(DWH)は、Snowflake の中心的な機能です。
ここには、データ統合やデータロード中のデータ変換、Time Travel 機能による任意データへのアクセス、データマスキング等、豊富な機能がそろっています。
Snowflake のデータウェアハウスとデータレイク S3 の紐づけ方法としては、以下の選択肢が考えられます。
- COPY INTO による一括ロード(バッチ方式)
- Snowpipe による自動データインジェスト(自動ロード方式)
本記事では基本となる一括ロード方式を紹介します。
なお、Snowflake 上でデータ変換をする(ELTアプローチ)ケースについては、dbt 等の支援ツールもありますが、データ変換機能については本項の紹介レベルにとどめます。
Snowflake のデータウェアハウスの起動にあたっては、データ利活用の前提となる初期設定(セキュリティ対応、コスト管理、スキーマ作成等)が必要になりますので、後述の想定利用シナリオにて解説します。
データ分析
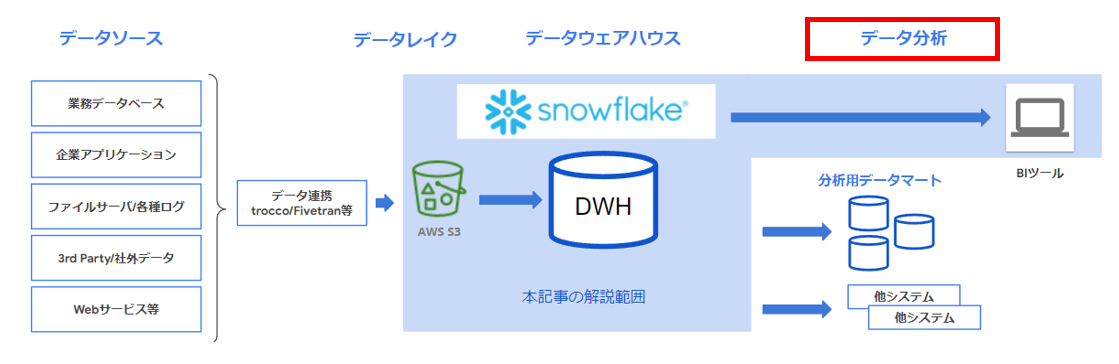
最後に、BI ツール Tableau Desktop を例に、Snowflake のデータ参照方法を解説します。
Snowflake データウェアハウスからデータマートへの展開は、ETLツールでデータマートを作成したり、Snowflake 内にデータウェアハウスのテーブルを解析してデータマートとなるテーブルを作成する等の方法が考えられますが、本記事ではBI ツールからの接続を解説するため、紹介にとどめます。
図の構成要素について、簡単に概要を説明しました。 以下では、実機上での設定例について解説していきます。
想定利用シナリオに基づく Snowflake の使い方
- データウェアハウス( Snowflake )の初期設定
- データレイク( S3 )とのデータ連携
- BIツール( Tableau )から Snowflake
への接続確認の順で実機設定を解説します。
Snowflake のEdition はEnterprise とし、S3 提供クラウドであるAWS を起動先に選定します。(「Snowflake とは」参照)
a.システム管理者によるデータウェアハウス初期設定
初期構築担当を「システム管理者」とします。
システム管理者がクラウド環境構築で気にすべきことは、まずセキュリティ関連です。
こうした作成作業は、今後のメンテナンス省力化のため、SnowSQL(CLIクライアント)を導入しスクリプト化しておくのが望ましいですが、ここでは作業環境をシンプルにするため、ブラウザ(Snowflake コンソールのWorksheets) からコマンドを実行します。
デフォルトのSnowflake アカウント(ACCOUNTADMIN ロール等)の利用は初期設定等、最低限にとどめ、テーブルを作成したり、参照するユーザーは別に作成するよう計画します。
これを怠り、ACCOUNTADMIN ロールでDBオブジェクトを作成したりすると、他ユーザーでは権限がなく操作ができないことも発生します。
ここでは一連の流れの確認をしやすいようACCOUNTADMIN ロールで作業し、別ロールをつかうべき作業は言及する形をとります。
参考:ユーザー管理 | Snowflake Documentation
※ユーザー/ロールの作成は、通常、USERADMINロールを利用
タイムゾーンの修正
次にログの確認がしやすいようタイムゾーンの修正をします。デフォルトが米国(
America/Los_Angeles)のため、日本標準時(JST)か協定世界時(UTC)に設定します。ここではグローバル観点でUTCとしています。
SQLTEXT例
SHOW PARAMETERS like 'TIMEZONE' IN ACCOUNT;
ALTER ACCOUNT SET TIMEZONE = 'Etc/UTC';
SHOW PARAMETERS like 'TIMEZONE' IN ACCOUNT;
ログについては、Snowflake 管理コンソール左ペインのActivity > Query History で確認できます。
参考:クエリ履歴の管理
クラウド課金リスク対策
最小限のセキュリティ設定を行った後は、クラウド課金リスクに備えます。
Snowflake を操作していると何らかのネットワークエラーでSnowflake との通信が遮断されるケースがありますが、この時、SQLクエリが実行中のままだと課金が発生します。
こうした無駄を避けるため、通信断の際は、クエリを停止するパラメータを有効にします。(下記例では変更前後のパラメータ情報をエビデンスとして取得します)
SQLTEXT例
SHOW PARAMETERS like 'ABORT_DETACHED_QUERY' IN ACCOUNT;
参考:ABORT_DETACHED_QUERY
ALTER ACCOUNT SET ABORT_DETACHED_QUERY = TRUE;
SHOW PARAMETERS like 'ABORT_DETACHED_QUERY' IN ACCOUNT;
新規データベースの作成
初期設定の最後に、新規データベース「TESTDB01」を作成します。
※本操作は、通常、SYSADMINロールを利用
このデータベースは下記「TESTDB01.PUBLIC」の通り、デフォルトのpublic スキーマが利用できます。(別スキーマの作成も可能ですが、ここではデフォルトのままとします)
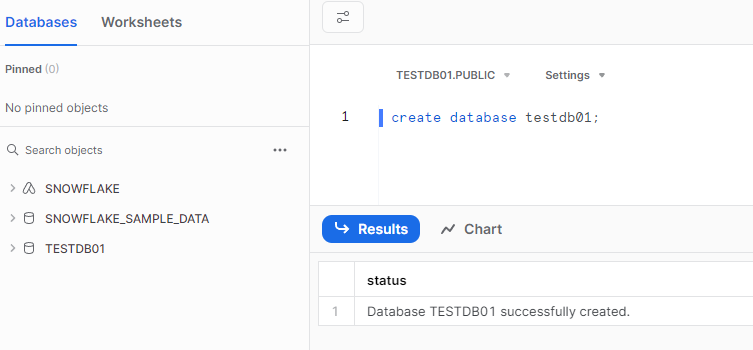
SQLTEXT例
create database testdb01;
次にテーブル「TESTTABLE01」を作成します。
S3の保管しているサンプルデータのcsv は下記のとおりですので、これらを格納できるテーブルを作成します。
State,Gender,Year,Top Name,Occurences
AK,F,1910,Mary,14
AK,F,1911,Mary,12
(省略)
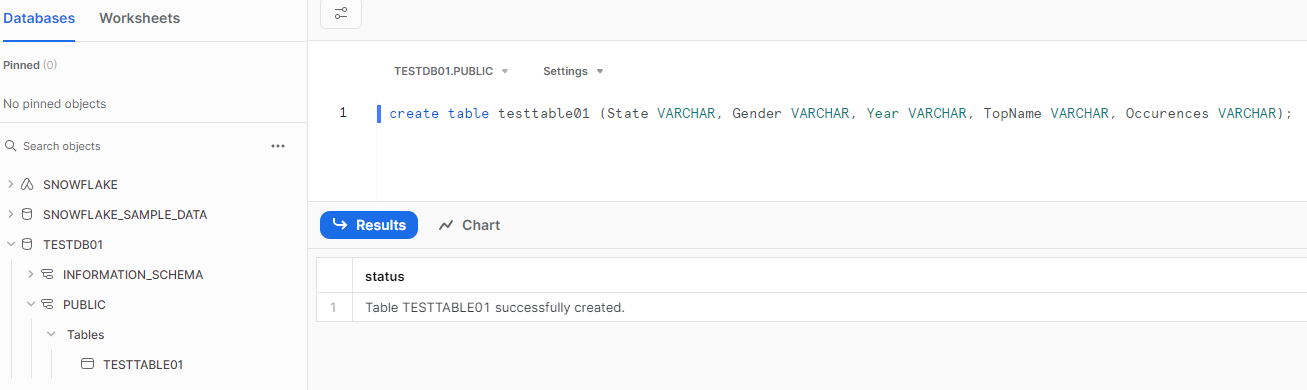
SQLTEXT例
create table testtable01 (State VARCHAR, Gender VARCHAR, Year VARCHAR, TopName VARCHAR, Occurences VARCHAR);
このテーブルはTESTDB01データベースのpublic スキーマ配下に作成されます。
テーブルの指定を正確に行うと「select * from testdb01.public.testtable01;」のようなDB名、スキーマ名、テーブル名の順になります。
データレイクとデータウェアハウス連携設定
S3 とSnowflake の連携は、「Snowflake ストレージ統合」を構成することがセキュアなアクセスへの実現方法とされています。
参考:オプション1:Amazon S3にアクセスするためのSnowflakeストレージ統合の構成 | Snowflake Documentation
下記ポイントを押さえながら設定していきます。
- データのあるS3 バケットへのアクセス権は読み取り専用
- Snowflake と信頼関係のあるIAM ロールを作成する
AWS ( S3 )側初期設定1
検証用S3 バケットとして、デフォルト設定で下記の通り作成しています。
バケット名は、「20231105-snowflake-test」、ディレクトリ名は「test01」です。
s3://20231105-snowflake-test/test01/
上記バケットへアクセスできるIAM ポリシー「20231105_snowflake_access」を作成します。(読み取り専用です)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:GetObjectVersion"
],
"Resource": "arn:aws:s3:::20231105-snowflake-test/test01/*"
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::20231105-snowflake-test",
"Condition": {
"StringLike": {
"s3:prefix": [
"test01/*"
]
}
}
}
]
}
IAMポリシーと同名ですが、IAM ロール「20231105_snowflake_access」を作成します。(別名でも問題ありません)
このIAM ロールに含めるIAM ポリシーは作成済みの「20231105_snowflake_access」です。
この段階では、Snowflake 側のストレージ統合設定が終わっていないので、一部ダミー情報を入力して作成します。
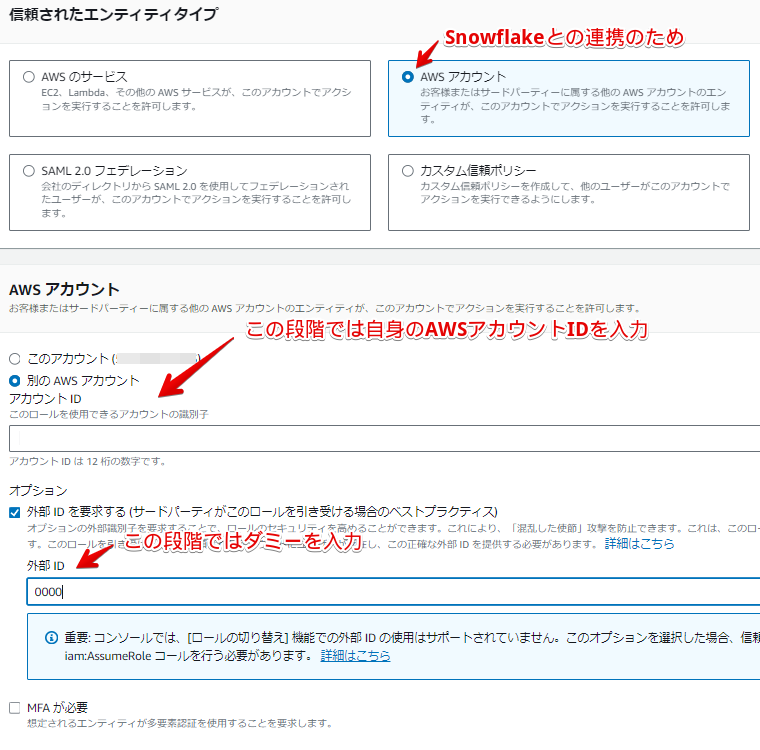
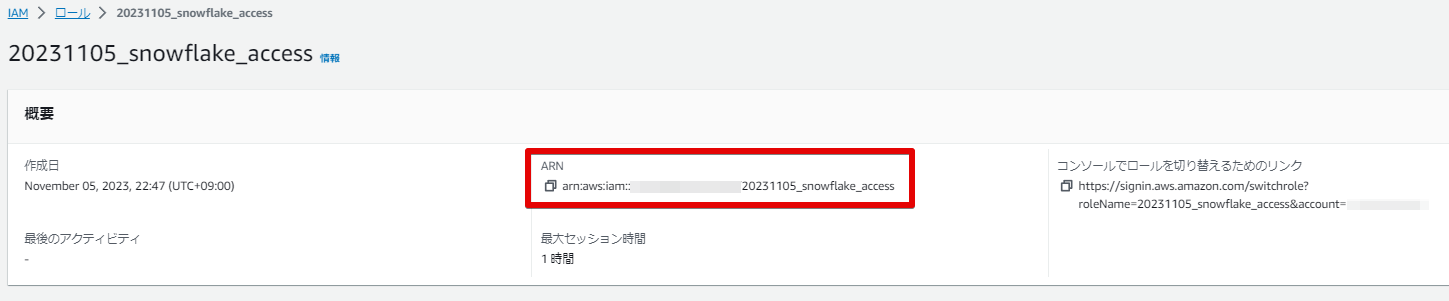
IAM ロール作成後は、後続で利用する下記「ARN」情報をメモして、次の手順に進みます。
Snowflake 側初期設定1
Snowflakeでクラウドストレージ統合「Snowflake_S3_Test」オブジェクトを作成します。
この作業は、システム管理者(ACCOUNTADMIN ロール)が行います。
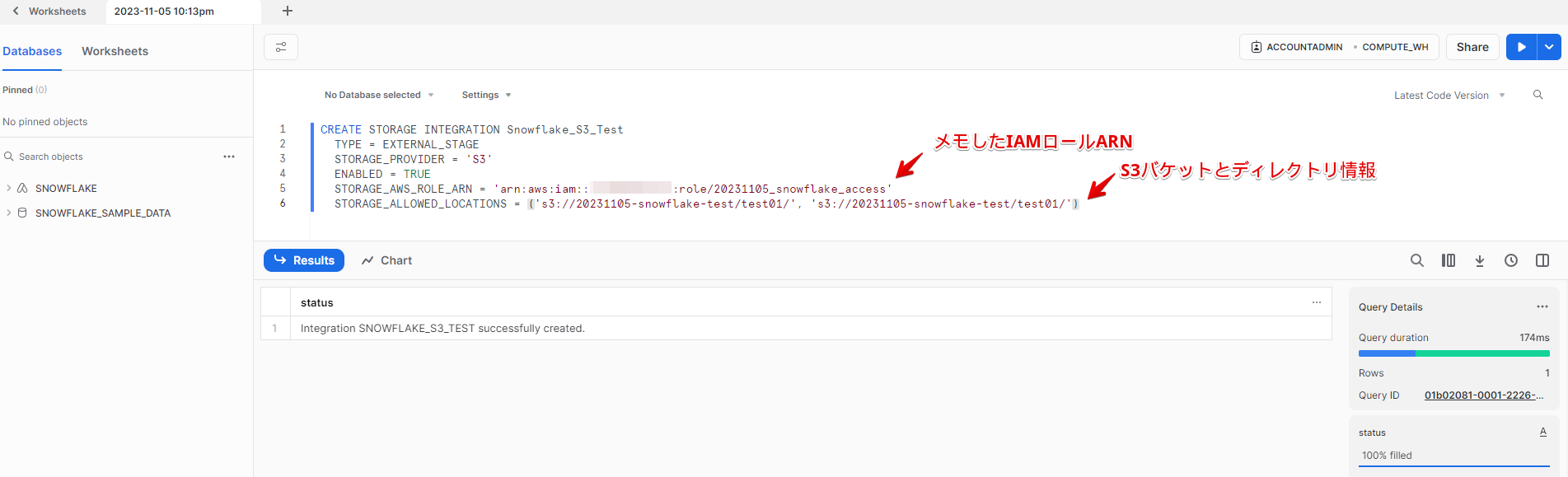
SQLTEXT例
CREATE STORAGE INTEGRATION Snowflake_S3_Test
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = 'S3'
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::xxx:role/20231105_snowflake_access'
STORAGE_ALLOWED_LOCATIONS = ('s3://20231105-snowflake-test/test01/', 's3://20231105-snowflake-test/test01/')
作成したクラウドストレージ統合オブジェクトには、AWS と信頼関係を結ぶための情報が含まれているので、確認します。
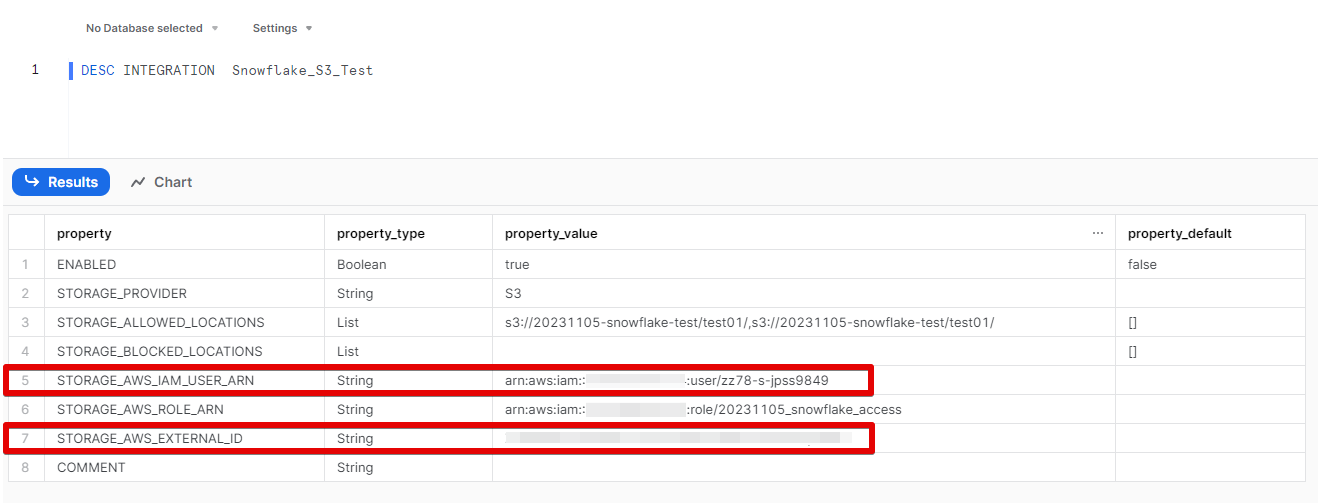
SQLTEXT例
DESC INTEGRATION Snowflake_S3_Test
これでSnowflake 側のAWS情報が取得できるので、上図2つの赤枠(Snowflake 側のARN情報と外部ID情報)をメモします。
AWS( S3 )側初期設定2
AWS初期設定1 で作成したIAMロールに戻り、信頼関係タブをクリックします。
先ほどメモしたSnowflake 側のARN情報と外部IDを下記に入力して保存します。
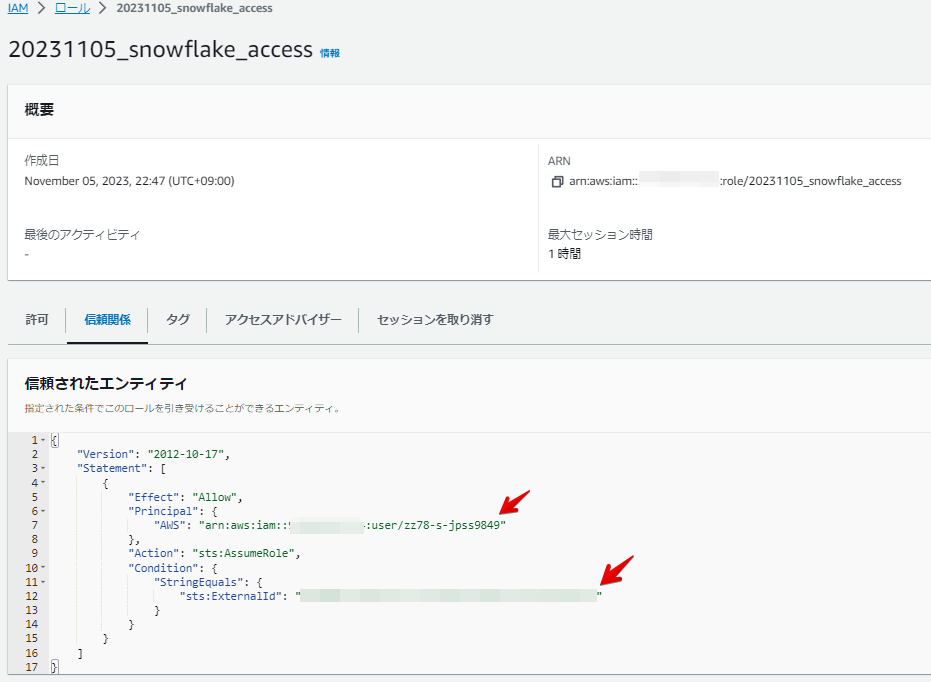
これでAWS S3 とSnowflake の信頼関係が設定されます。
Snowflake 側初期設定2
Snowflake からS3バケットにアクセスできるように、外部ステージ(クラウドストレージ統合オブジェクトを参照する仕組み)を作成します。
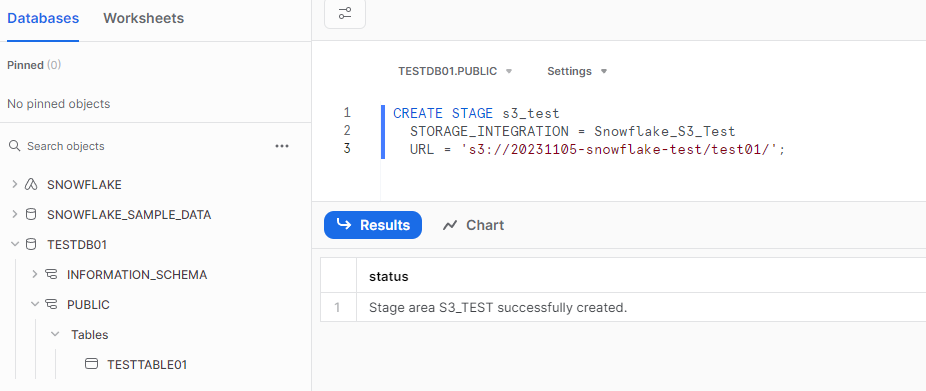
SQLTEXT例
CREATE STAGE s3_test
STORAGE_INTEGRATION = Snowflake_S3_Test
URL = 's3://20231105-snowflake-test/test01/';
Snowflake へのデータコピー準備が終わりました。
Snowflake へのデータコピー
前述しましたが、本記事では、下記方式を解説します。
- COPY INTO による一括ロード(バッチ方式)
データウェアハウス初期設定で作成したデータベースのテーブルにS3 上のサンプルデータをコピーします。
このSQLは、クラウドストレージ統合オブジェクトの情報にあるS3バケット内のcsv データをコピーします。(本検証では1ファイル「TopBabyNamesbyState.csv」が対象になります)
また、このcsv データの1行目はヘッダ情報のためスキップオプションをつけています。
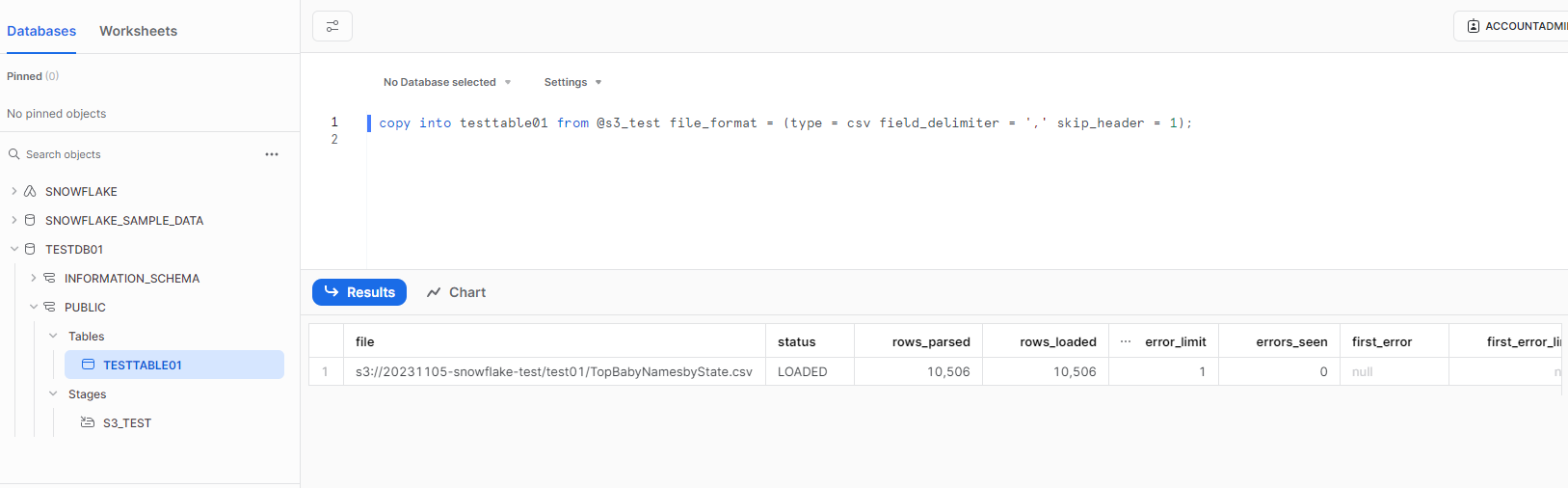
SQLTEXT例
copy into testtable01 from @s3_test file_format = (type = csv field_delimiter = ',' skip_header = 1);
テーブル内をselect すると、S3 バケット上のcsv データの内容が表示されます。
Snowflake データウェアハウスへのデータ取り込みに成功しました。
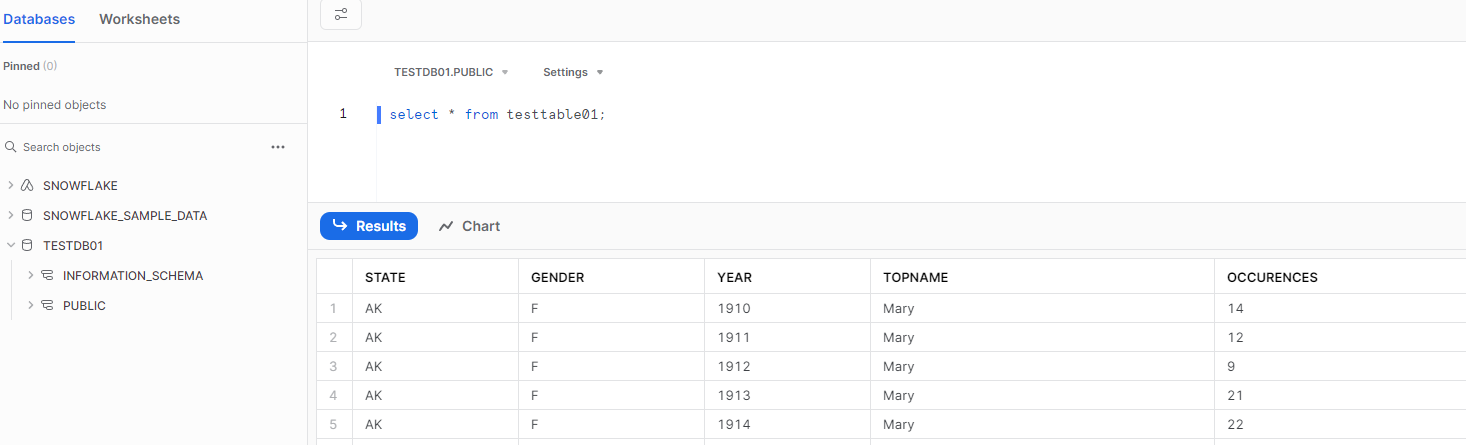
今回はシンプルに1ファイル1テーブルの例ですが、Snowflake の実際の運用では、データ変換やテーブル結合等、様々なデータ加工支援を可能にします。
BIツールの接続方法
それではBIツール Tableau からSnowflake に接続してみましょう。
BIツールの利用者は、これまで作業してきたシステム管理者ではなく、データ分析等を担当する役割をもったユーザーとなります。
BIツール利用者がシステム管理者権限でSnowflake にアクセスすることは避け、初期設定で作成したBIツールユーザー用のアカウントでSnowflake に接続します。
システム管理者=データ分析担当であったとしても、Snowflake へのアクセスユーザーは使い分けておくといいでしょう。今後の担当変更等の管理コストやセキュリティリスクが削減できます。
Tableau Desktop のインストール
データ分析担当のPC( Windows )にTableau Desktop をインストールします。
- Tableau Desktop をダウンロードしてインストールファイルを実行
参考:Tableau Desktop - Tableau Desktop 起動後、必要に応じて、無料トライアル版のライセンス認証を行う。
Snowflake 用 ODBC ドライバーをインストール
次に下記リンクからWindows 版の Snowflake 用 ODBC ドライバーをインストールします。(インストール中はTableau Desktop をいったん閉じてください)
参考:
ODBC - Snowflake Developers
Tableau と Snowflake の接続
ODBCドライバー導入が終われば、Snowflakeに接続します。
Tableau Desktop を起動し、赤枠を選択していくと、Snowflakeの認証画面が表示されます。
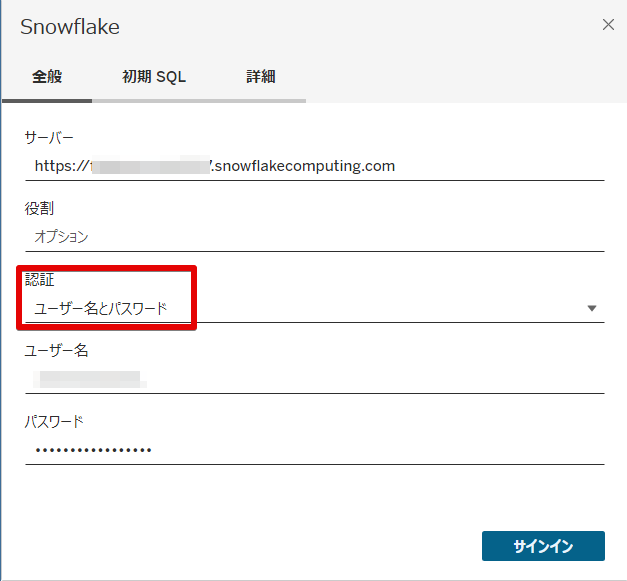
サーバー情報は、下記URL形式となります。認証方式は「ユーザー名とパスワード」を指定し、サインインします。
BIツールでサインインし、Snowflake のテーブルを参照するところまでくれば、グラフ作成、ダッシュボード化の分析業務が可能になります。
ここでは、Tableau とSnowflake の接続確認の参考で、参照テーブルからバブルチャートを作成してみましたが、Tableau 自体の操作方法となりますので、詳細は省略させて頂きます。

tableau の勉強方法の記事へリンク
まとめ
想定ケースについて、作業の進め方を解説してきました。
流れをおさらいすると、データソースに配置したサンプルデータをSnowflake(初期設定済)にコピーし、BIツールからのSnowflake への接続です。
本記事では、これらのSnowflake に関わる基本的な操作のご紹介でしたが、
- セキュリティ
- 複数データソースからのデータコピー自動化
- データの効率的な変換
等、BIツールでのダッシュボード化の前に検討すべきことがたくさんあります。
データ利活用、分析といったユーザー本来の業務に取り組むことは、Snowflake により柔軟になりましたが、一連の流れをデータ基盤として構築し、正常な環境を維持していくためには、専門的なスキルが必要になります。
専門家集団のサポートの元、データ利活用、分析の基盤をSnowflake で構築してみませんか?
弊社クリエイティブホープでは、 Snowflake を活用した小さく始めるデータ分析、データ分析構築を得意としております。マーケティング視点に基づいたデータの収集から基盤の構築、BIツール設計まで一気通貫でサポート可能です。
データ分析、データ分析構築のミニマムスタートにご興味のある方はお気軽にご相談ください。
なお、「小さく始めるデータ分析と基盤構築ガイドブック」のeBookもご用意しておりますので、併せてご覧いただけますと幸いです。
本記事があなたの Snowflake の使い方やデータ基盤の構築にお役立ちいただけますと幸いです。